AI时代测试用例从“手工编写脚本”演化为“智能自适应”
在AI智能体深度融入办公场景的未来,即便编码工作完全由AI智能体完成,测试活动依然不可或缺,甚至会更加重要。原因在于,代码生成只是软件生产的一环,而质量保障涉及更广泛的维度,且AI生成代码本身会引入新风险以及陡增都算力成本。如果以OpenClaw(将其视为具有通用工作流理解、交互和执行能力的AGI)部署应用为代表事例,未来5-10年,测试用例将完成从“脚本确定性”到“智能自适应”的演化。
一、测试用例设计:从“手工编写脚本”到“意图驱动设计”
1.1 传统设计的局限
以往,测试人员根据需求文档逐条编写测试脚本,流程如下:需求分析 → 编写测试点 → 转化为可执行脚本(如Selenium、JUnit)。这个过程高度依赖人工,不仅耗时,还容易因需求理解偏差导致漏测,且难以覆盖所有业务场景。
1.2 意图驱动设计的概念
意图驱动设计,是指测试智能体直接理解我们(产品经理、业务专家)用自然语言表达的业务意图,自动生成覆盖正常、异常、边界场景的测试用例。这里的“意图”不再是技术细节,而是业务目标,例如:“确保员工报销流程顺畅,且金额超过5000元需经过二级审批。”
1.3 技术实现路径
多模态需求理解:测试智能体接入产品文档、会议记录、原型图甚至语音描述,利用大语言模型(LLM)和知识图谱,抽取出实体(如“员工”“报销单”)、动作(“提交”“审批”)和规则(“金额>5000需二级审批”)。
场景树自动生成:基于业务规则,智能体通过符号推理或强化学习,生成所有可能的操作路径。例如,正常流程(金额<5000)、异常流程(金额>5000但无二级审批)、边界情况(金额=5000)、并发场景(多人同时提交)等。
测试数据智能构造:智能体根据字段类型和业务规则,自动生成符合语法和语义的测试数据,如合法的员工ID、报销类别,以及边界值(金额=0、负数、超大值)。对于涉及隐私的数据,还会自动脱敏或合成。
预期结果自生成:基于业务规则,智能体为每个用例生成预期结果。例如,审批通过后系统应更新状态并发送邮件;若缺少二级审批,则流程应被阻塞并提示错误。
多语言/多平台适配:智能体根据被测系统(Web、移动端、API)自动生成对应格式的测试用例描述或可执行代码(若需要),但更常见的是生成一种中间表示(如行为树),供执行引擎使用。
1.4 与传统设计的对比
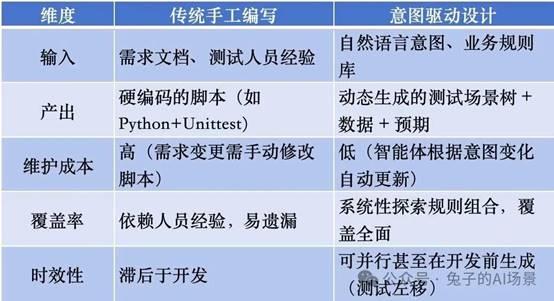
1.5 在办公场景中的实例
某公司报销流程变更:需增加“部门预算校验”。产品经理在需求会议上说:“报销金额不能超过部门当月剩余预算,超过则驳回并提醒预算员。”测试智能体实时监听会议,将这句话转化为:
实体:部门、当月剩余预算、报销金额;
规则:报销金额 ≤ 剩余预算 → 通过;否则驳回,通知预算员;
生成测试用例:
①报销金额 = 剩余预算 - 1 → 通过;
②报销金额 = 剩余预算 → 边界通过;
③报销金额 = 剩余预算 + 1 → 驳回,触发通知;
④部门预算被其他项目占用时提交报销 → 并发测试;
⑤预算数据未同步时提交 → 异常处理测试。
这些用例立即存入测试库,供后续执行使用。
二、测试用例执行:从“定时定点运行”到“混沌式持续探索”
2.1 传统执行的局限
传统测试多在特定环境(测试环境)和特定时间(如夜间构建后)执行,覆盖有限场景。这种方式无法捕捉生产环境中的偶发问题、非预期交互,且测试环境与生产环境差异导致漏测。
2.2 混沌式持续探索的概念
混沌式持续探索,是指测试智能体7×24小时在类生产环境(如影子模式、混沌实验平台)中持续、随机地探索系统行为,通过主动注入故障、模拟用户非典型操作、压力干扰等方式,主动发现系统的脆弱点和未知缺陷。
2.3 技术实现路径
影子模式与流量镜像:在生产环境旁部署影子应用,实时复制真实用户请求并修改(如注入延迟、篡改数据),发送给被测系统,同时观察响应。智能体分析影子响应与真实响应的差异,发现潜在问题而不影响真实用户。
智能探索算法:结合强化学习,智能体学习系统各模块的“兴趣点”(如高频操作、复杂逻辑模块),并倾向于探索尚未覆盖的路径。类似AlphaGo的蒙特卡洛树搜索,智能体在状态空间中模拟未来,寻找可能导致异常的路径。
混沌工程自动化:智能体自动设计混沌实验,并评估影响范围,例如:
①随机关闭某个微服务实例,观察系统降级机制。
②在网络层注入延迟或丢包,测试前端超时重试逻辑。
③模拟数据库连接池耗尽,检查熔断机制。
异常监控与实时反馈:在探索过程中,智能体实时收集指标(响应时间、错误率、资源利用率)和日志,通过异常检测算法(如时序预测、模式匹配)发现系统行为偏离。一旦发现异常,立即停止探索并记录复现步骤。
2.4 与传统执行的对比
2.5 在办公场景中的实例
企业可以使用一套AI驱动的审批系统。某日凌晨,测试智能体在影子模式下随机组合操作:先创建一个紧急采购申请,又在审批期间模拟审批人网络断连,同时注入预算服务延迟。它观察到:虽然审批最终通过,但前端在审批人恢复连接后显示了错误状态,需手动刷新才能更新。智能体捕捉到这一异常,记录下完整的操作序列和网络条件,创建了一个高优先级的缺陷报告,附带复现步骤和根因初步分析(前端WebSocket重连机制缺陷)。
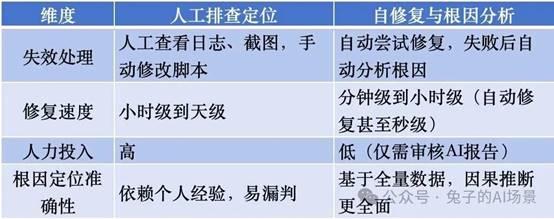
三、测试用例维护:从“人工排查定位”到“自修复与根因分析”
3.1 传统维护的痛点
当UI元素改变(如按钮ID修改)、接口字段变更或业务规则调整,大量测试脚本失效,需要人工逐一排查定位。这个过程枯燥、耗时,且容易引入新错误。
3.2 自修复与根因分析的概念
自修复是指测试执行失败时,智能体自动识别失败原因(如定位器失效、环境问题),并尝试自我修复(如重新寻找元素)或动态调整测试步骤,使测试继续运行。根因分析则是深入分析失败背后的代码或配置缺陷,生成详细报告,甚至联动编码AI进行修复。
3.3 技术实现路径
自修复机制:
①多模态定位器融合:传统UI测试依赖单一属性(如ID)。智能体结合计算机视觉(识别按钮图像)、OCR(识别文本)、DOM树结构上下文,当ID变化时,仍能通过文本“提交”或位置找到元素。
②自适应重试策略:如果某步骤失败,智能体判断是暂时性异常(如网络抖动)还是永久性失败。若是前者,等待后重试;若是后者,尝试替代操作(如点击附近元素、执行快捷键)或跳过该步骤(如果非关键)。
③自我调整测试数据:若失败因数据过期(如订单状态已变更),智能体可调用API重置数据或生成新数据,然后重新执行。
根因分析:
①全链路追踪:智能体自动关联测试执行时的日志、调用链、指标,构建事件时间线。例如,失败时发现某个微服务返回500错误,追溯其调用栈,定位到具体代码行。
②因果推断:利用统计和机器学习方法,从大量执行数据中分离相关性和因果性。例如,多个用例失败都涉及“预算服务”,智能体推断预算服务升级是根因。
③变更关联分析:智能体实时监控代码库、配置中心的变更,将测试失败与最近的代码提交或配置修改关联。如果发现某个提交恰好修改了失败相关的模块,即锁定嫌疑。
④自动报告与修复建议:智能体生成包含根因、影响范围、复现步骤和修复建议(如“将预算服务接口返回字段名从‘balance’改为‘remainingBudget’”)的报告。在获得授权后,可直接触发编码AI进行修复并提交PR评审。
3.4 与传统维护的对比
3.5 在办公场景中的实例
某次前端改版,将“提交报销”按钮的ID从submit_btn改为btn_submit。测试智能体执行报销流程时,无法点击按钮。它立即启动自修复:
视觉识别:在按钮位置找到图像,文本为“提交”,确认这是目标按钮。
尝试多种定位方式:使用XPath“//button[text()=‘提交’]”成功定位,点击继续。
记录该变化,并更新内部元素知识库,供后续用例使用。
同时,由于自修复成功,测试继续执行。但后续断言失败:预期出现“提交成功”提示,却出现“系统繁忙”。智能体分析日志,发现后端新引入的权限校验逻辑出现了空指针异常,原因是一个新加的字段在部分用户数据中缺失。智能体追溯到代码提交记录,锁定开发智能体A的本次修改,并生成详细报告,附上修复建议(添加字段判空)。开发智能体A收到报告后,1分钟内修复了问题。
四、协同构建自适应测试生态系统
三个转变并非孤立,而是紧密协同,构成一个完整的自适应测试生态系统:
意图驱动设计源源不断生成覆盖业务规则的测试用例种子,作为探索的起点。
混沌式持续探索在动态执行中不断发现未知边界,这些新路径又反馈给设计模块,丰富场景库。
自修复与根因分析确保测试用例在环境变化中保持有效,同时将发现的缺陷根因反馈给设计和编码智能体,用于优化未来生成的质量。
最终,测试本身成为一个自进化的智能体,与编码智能体协同,使软件交付从“构建-测试-修复”的线性流程,转变为“意图-生成-验证-演化”的闭环,极大提升效率和质量。
五、对测试人员的新要求
虽然测试智能体承担了大部分工作,但测试人员并未失业,而是转型为更高层次的角色:
意图定义者:清晰、无歧义地表达业务意图,训练和校准测试智能体的理解能力。
策略架构师:设计探索的奖惩机制、风险偏好,决定哪些区域需要重点探索。
结果审核员:审核AI生成的根因分析和修复建议,确保其符合业务逻辑和长期目标。
复杂场景设计者:处理AI难以理解的模糊需求、跨领域业务规则,提供高层级测试策略。
未来已来,拥抱变化,我们应该聚焦于更具创造性和决策性的工作活动。
